nSpire AI · Founding PM
Vera — AI hiring intelligence, zero to shipped in a week
Hiring is stuck in a doom loop: resumes are gameable, AI made them worse, and the first real capability signal arrives too late. Vera fixes the timing problem.
Problem
Hiring teams receive 200+ applicants per role but can only meaningfully interview 15. The first real capability signal arrives when a hiring manager finally sits with the candidate — by then 70% of those interview slots are already wasted on people who clearly aren't right. AI has made it worse: candidates now mass-apply with optimized resumes and cover letters that look indistinguishable from genuine standouts. The traditional signals (resume keywords, cover letter polish, application completeness) have been gamed to the point of meaninglessness. Existing tools (HireVue, Metaview, BrightHire) record interviews but don't extract structured signal; ATS systems focus on pipeline management, not evaluation.
Solution
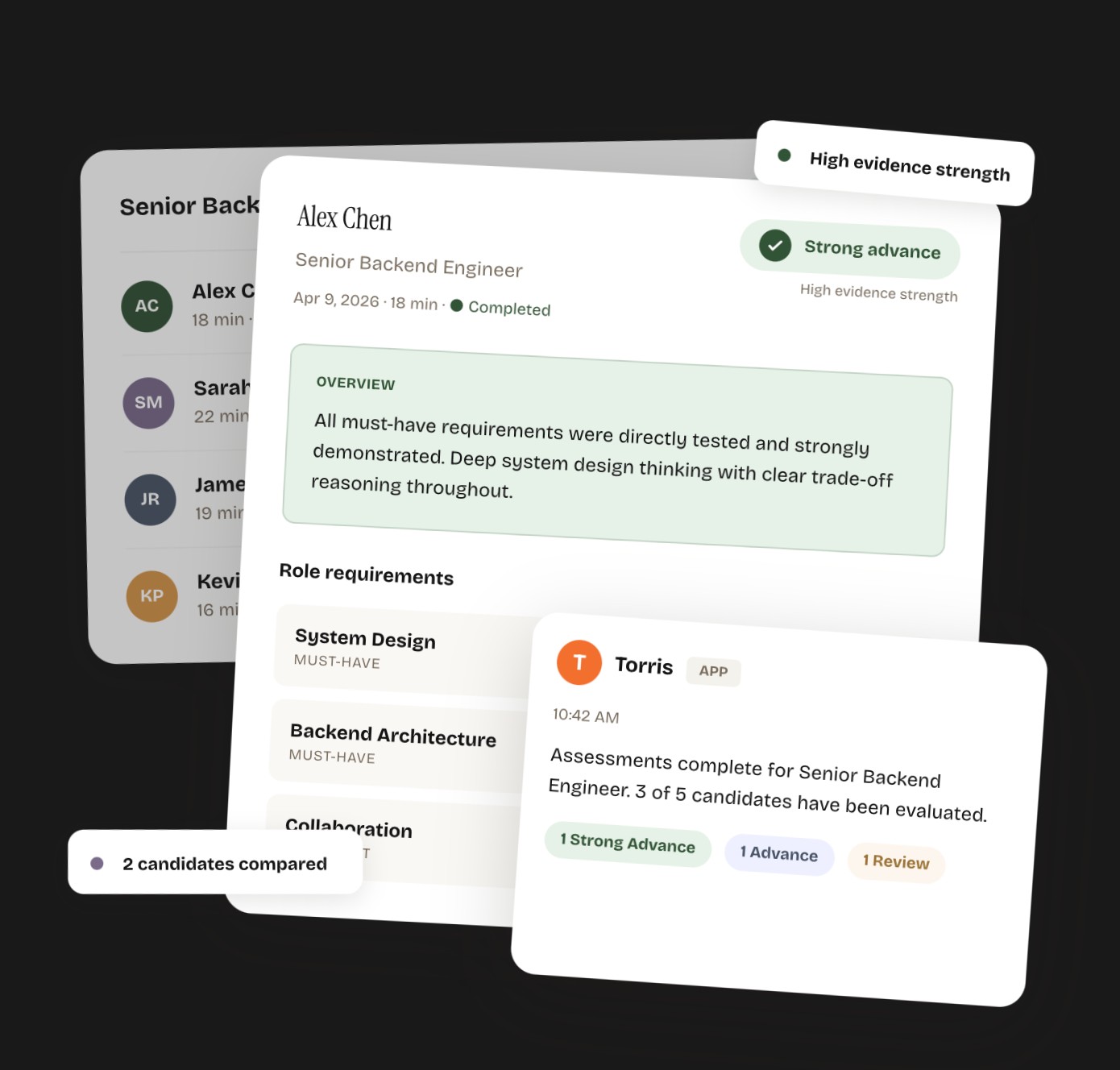
Vera (internal codename Synthia) introduces an intelligence layer *before* the hiring team. It conducts a structured, role-specific AI interview (6–7 questions plus dynamic follow-ups), captures multimodal evidence (video, audio, transcript), and generates a decision-ready report inside the customer's ATS — starting with Ashby. The report uses evaluation bands instead of numeric scores (fairness-aware) and presents must-have coverage, evidence excerpts, risks, and a single recommendation: Advance, Review, or Hold. Three separate agents (Planner, Interviewer, Analyzer) enforce discipline — the model that designs the rubric isn't the one judging the candidate.
Why it matters
Hiring managers get real capability evidence before they spend a single minute. Recruiters reclaim the hours previously burned on weak phone screens. Companies move from interviewing 15 of 200 (by gut) to interviewing the right 15 (by evidence). And nSpire gets a two-sided flywheel: Theo collects longitudinal preparation data on candidates; Vera collects interview performance data on hires. Together they're the only product that links *how someone prepares* to *how someone performs* to *what gets hired* — a dataset no incumbent can replicate.
Success metrics
-
1 week
Zero to shipped
-
$500K / 90 days
Internal launch sprint TCV target
-
Live
Ashby integration
-
$1.5K–$10K/mo
Pricing tiers
-
$145K
Existing nSpire ARR base
-
40,000+
Warm channel (Theo users)
-
3 tiers · 20–25 target deals
Customer segments
The doom loop
“Your hiring team interviews 15 people. Maybe 4 are right. Here’s why that’s structural, not personal.”
Hiring used to have a simple failure mode: too many resumes, not enough time. Now it has a structural one. AI gave candidates the ability to generate polished, keyword-optimized applications at scale. A single person can mass-apply to hundreds of roles in a day with tailored resumes that look indistinguishable from genuine standouts.
So your team makes high-stakes decisions from proxies that no longer carry information. You get 200 applications. You interview 15. But the basis for picking those 15 — resume quality, cover letter clarity — tells you almost nothing about whether someone can actually do the work.
The first real signal arrives when a hiring manager sits down with the candidate. By then, 70% of those interview slots are wasted. The problem isn’t bad candidates. The problem is that the first meaningful evidence arrives too late.
Vera fixes the timing problem.
What I actually did (founding PM playbook)
Week 1 — clarity. Before we wrote a line of code, the team had a 2-hour alignment call. I pushed for one decision: who is Vera for? Recruiters? Hiring managers? Both? “Both” is the answer that kills products. We landed on: pre-hiring-manager interview intelligence. Recruiters trigger; hiring managers consume. That single sentence rewrote the report design, the rubric framework, what’s in scope for the MVP, and what we cut.
Week 1 — ship. Built Vera zero to shipped in seven days. Validated with real recruiters via overnight calls. Integrated into the nSpire platform. Designed paywall, tiering, and Ashby integration.
Weeks 2–4 — pilots. Onboarded the first hiring teams. The product moment that mattered: when I pulled up a prospect’s own job description live in a demo and ran it through the Planner. In ~45 seconds, Vera converted their JD into a structured interview plan with role requirements ranked by criticality, evidence definitions, and must-have coverage. Every time: silence, then “can you do that for our other open reqs too?”
Weeks 4–12 — the 90-day war plan. Wrote and now executing the GTM playbook: $500K TCV in 90 days through a deal mix of enterprise ($40–80K), growth-stage ($12–36K), and SMB ($3–10K). 60–80 qualified opportunities, 20–25 signed deals, $25K weighted average TCV.
Build-in-public. Designed a 32-post LinkedIn campaign across 8 team members — each writing from their actual role (engineer, designer, sales, AI, COO, founder) about the real work, not corporate messaging. 4 weeks. Problem → product → craft → conversion arc.
Design principles (verbatim from the PRD)
- Evidence over impression. Signal design prioritizes transcript-backed, explainable evidence over vague impressions.
- Evaluation bands over numeric scoring. Bands beat scores for fairness and usability. Cognitive load drops. Bias scrutiny gets easier.
- Workflow fit over AI complexity. “If a hiring manager reads the report and thinks ‘this helps me decide who to interview next,’ then the product is delivering value.” Nothing else matters at MVP.
What we deliberately don’t measure
Every one of these was on an early list. Every one got cut:
- Confidence (as a general trait)
- Charisma
- Eye contact or facial expression
- Accent or speech style
- How polished an answer sounds
The admissibility test: Can this signal be justified as evidence of capability to do the work of the role — in a way we’d be comfortable explaining to the candidate, the hiring manager, and a regulator? Confidence can’t. Charisma can’t. Eye contact definitely can’t. We built for capability, not impressiveness.
What I’d do differently
The first sprint, we tried building this with a single agent that planned, interviewed, and evaluated. It drifted — the model that designed the rubric was also judging it, with subtle bias toward validating its own plan. Worse, it kept probing on things it found interesting rather than things the rubric required. Coverage became inconsistent.
Splitting into three agents (Planner → Interviewer → Analyzer) is boring infrastructure. It’s also the reason the reports are trustworthy.
Long-term moat
Vera + Theo creates a hiring intelligence flywheel no incumbent can match:
- Theo collects how candidates prepare.
- Vera collects how they perform in interviews.
- Together: the first longitudinal dataset linking preparation, interview behavior, and hiring outcomes.
This is not in the MVP. But it’s the reason the MVP exists.